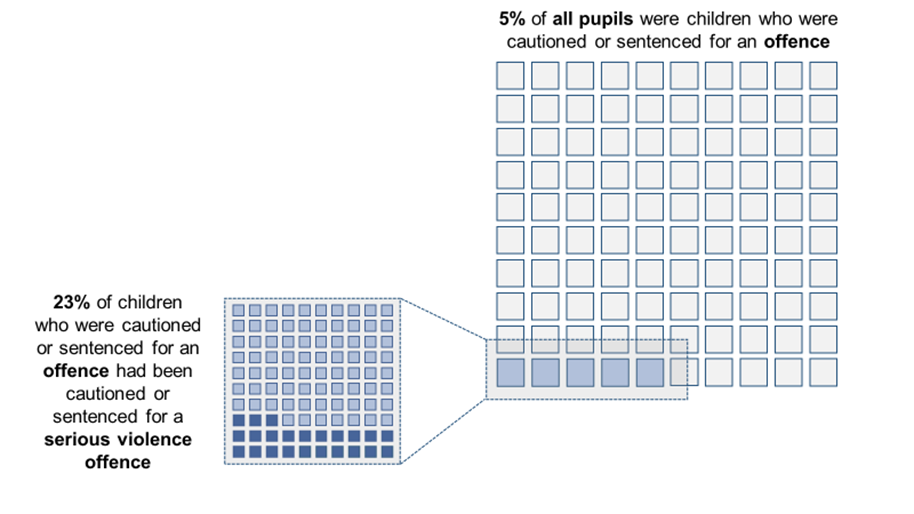
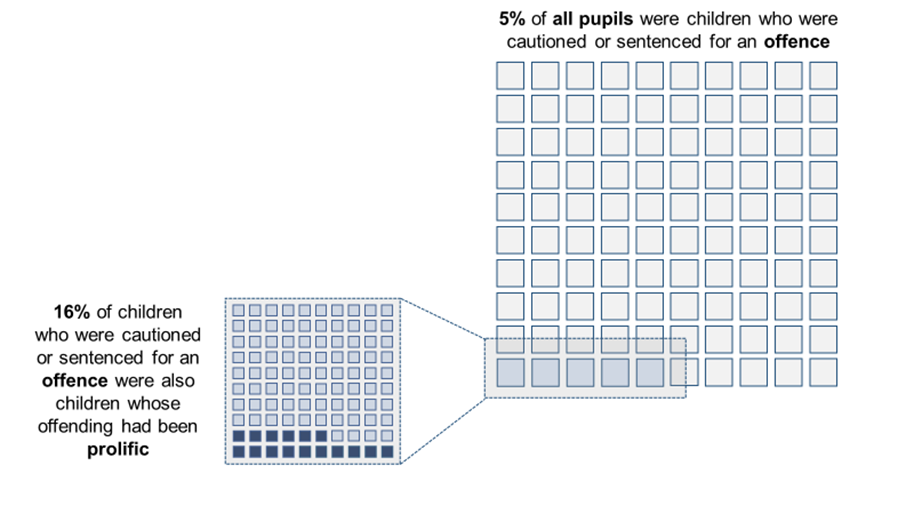
Education, children's social care and offending
Descriptive statistics - Technical Note
March 2022
This technical note sets out details of the data share between the Ministry of Justice (MoJ) and Department for Education (DfE), and the matching process between the Police National Computer and National Pupil Database data.
The technical note contains match rates from the first iteration of the DfE-MoJ data share that was carried out in 2019, however the dashboard was created using data from the second iteration of the data share that was completed in 2022. Therefore, the figures below do not directly apply to the data contained in the dashboard.
We will be updating the technical note shortly to reflect match rates from the second iteration of the data share.
Data sources and matching methodology
This section sets out details of the data share between the Ministry of Justice (MoJ) and Department for Education (DfE), and the matching process between the MoJ and National Pupil Database data.
Data sources
Data from several large datasets were brought together in this data share, as permitted by the Ministry of Justice’s common law powers and various prescribed legislative data sharing powers available to DfE[1]. A brief description of the two main datasets is included below:
National Pupil Database (NPD) – DfE
A wide range of information about pupils and students which provides evidence on educational performance and context. The data includes detailed information about pupils’ test and exam results, prior attainment, and progression between each key stage for all state schools in England. It also includes information about the characteristics of pupils in the state sector and non-maintained special schools, such as their gender, ethnicity, first language, eligibility for Free School Meals, awarding of bursary funding for 16-19-year-olds, information about Special Educational Needs, and detailed information about any absences and exclusions.
Police National Computer (PNC) – MoJ
This dataset includes recordable offences committed, with separate entries for each offence committed by a person, although only some information (e.g. personal characteristics) will be available through the linked data. The data analysed in this report is a subset of the total number of individuals. All individuals who commit an offence are recorded on the Police National Computer (PNC), this report is based on offenders from the PNC that were successfully matched to the NPD, covering the period 2000 – 2017.
How was the data matched?
The methodology used to match the data sources together was similar to that used in other MoJ data linking projects, such as the data share between MoJ and the Department of Work and Pension (DWP) and Her Majesty’s Revenue and Customs (HMRC)[2].
The data were matched using combinations of six demographic variables from the PNC and NPD: forename, middle name, surname, date of birth, gender, postcode, and the derived variable: full name.
Matching rules were agreed between MoJ and DfE and included combinations of at least four exact matches of the common variables. The majority of data was matched on rule 1 (exact names, date of birth, postcode and gender) accounting for 64% of all matches. In addition to full matching, partial matching was used to improve match rates when matching on forename, middle name and surname was not successful. As exact matching is very strict (either a word matches or it does not), partial matching improved match rates by including matches where the first two characters from forename, middle name or surname matched. Partial matching was also employed for Date of Birth (i.e. when date and month of birth were inverted) and postcode (i.e. by matching on the postcode sector, e.g. “SE14 5”, rather than the full postcode).
Alias information – alternative names and dates of birth recorded for the same offender – from the PNC was also included in the data share. Previous data shares have indicated that this information plays a key role in data matching reports. As such, multiple names and postcodes were provided for some offenders.
Match Rate
Not all offenders on the PNC were involved in the match to the National Pupil Database (NPD) as the NPD only began to record data from the 2001/02 academic year. Whilst attempting to match as many offenders on the PNC as possible, due to the limited time coverage of the NPD, it was only possible to match offenders between the ages of 10 and 32 as at December 2017. This meant the records of around 1.95 million offenders, aged between 10 and 32 years, from between 2000 and 2017 who were on the PNC were shared with DfE. Of those, around 1.51 million were matched and included in the final matched dataset after cleaning. A good match rate of around 77% was achieved. Figures in this publication are based on matched offenders only and, as a result, volumes will be lower than published statistics from individual data sources.
Matching Results
Multiple records for the same offender were included in the data matching exercise between the PNC and the NPD. DfE attempted to match each record separately to their data. This meant that there were five potential scenarios for each unique offender:
- One PNC record match to one NPD record
- One PNC record matched to many NPD records
- One NPD record to many PNC records
- Many PNC records to many NPD records
- No match between PNC and NPD
After matching, there was a match of one PNC record to one NPD record (scenario 1) for around 57% of offenders.
For scenario 2 and 3, the most reliable match was selected as follows:
- Using matching rule: selecting the record matched on the strictest match rule.
- Using data source: If multiple records shared the highest match rule, the data source was used to select a match.
- Tie: If multiple records are tied on both match rule and data source, the record is not included in the final matched dataset.
Scenario 4 and 5 were not included in the final matched dataset.
Representativeness of the matched dataset
The 1.51 million records in the final matched Police National Computer dataset were compared against the 441,493 records shared with DfE for data matching that did not match. Overall, the matched dataset had similar characteristics to the unmatched dataset in terms of gender and age, with some noted differences for ethnicity.
- The matched dataset was 73% male and 27% female (excluding unknown) which was broadly in line with the unmatched dataset (76% male and 24% female).
- The age breakdown of the matched dataset was similar to the unmatched dataset, although the matched dataset slightly under-represents older offenders and slightly over-represents young offenders. This is due to better matching rates for young offenders.
Figure 1: Age breakdown of matched dataset compared to unmatched dataset
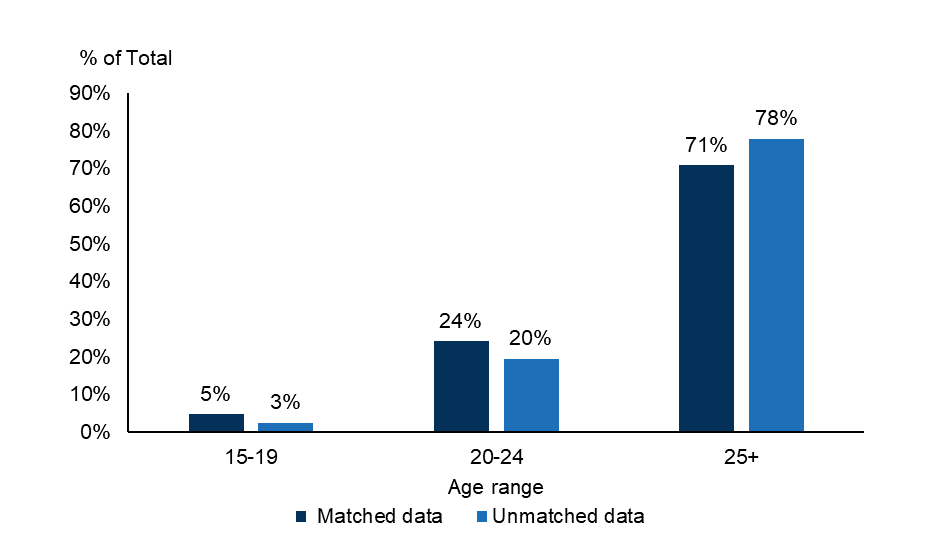
- Comparisons were also made between the matched and unmatched officer identified ethnicity. The comparisons in table 1 show a higher proportion of offenders from a “Black” and “Asian” background (8% and 6% of the matched data, compared to 3% and 4% of the unmatched data) and a slightly lower proportion from a “White” background.
Table 1: Officer identified ethnicity breakdown of matched data compared to unmatched data
| Matched data | Unmatched data | |
| White | 85% | 90% |
| Black | 8% | 3% |
| Asian | 6% | 4% |
| Other | 1% | 3% |
Caveats when using matched data
There are a number of caveats which should be considered when using the matched data:
- The matched data has been produced using administrative data sources whose main purposes are not solely statistical. Therefore, as with any large recording system, the data are subject to possible errors with data entry and processing. Quality assurance procedures, including cleaning of duplicated offender entries and checks for completeness and representativeness, have been applied to the matched data
- The comparisons on representativeness provide some assurances that the matched data is broadly reflective of the offender cohort, but it should be made clear that this is not the full offender population.
- The analysis in this report is based only on the final matched PNC dataset. Around 23% of offenders aged 32 and under were not uniquely matched to the NPD. Reasons for this include:
- They offended in England or Wales and were educated in Wales, Scotland, Northern Ireland or outside of the United Kingdom
- Different names were recorded (potentially due to the offender changing their name or reporting a different name) on the NPD and the PNC
- They have a common set of characteristics (i.e. the same name, date of birth and/or postcode) that make it difficult to determine a unique match across the datasets.
Match rates by age
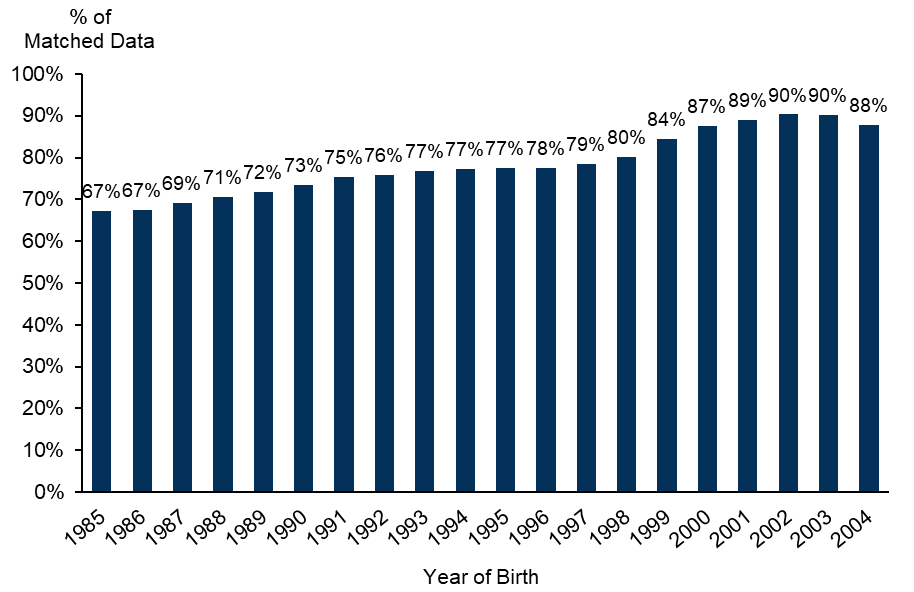
The overall match rate was around 77%, but a greater proportion of younger offenders were matched as they will have had a greater likelihood of being included in the National Pupil Database where matched data is available from 2002/03.
Figure 2: Match rates by year of birth
[1] How DfE share personal data - GOV.UK (www.gov.uk) (opens in new tab)
[2] http://www.gov.uk/government/statistics/experimental-statistics-from-the-2013-moj-dwp-hmrc-data-share (opens in new tab)